
The Hybrid Architecture: Combining Serverless and Microservices in 2026
For years, the industry swung between microservices and serverless. Teams rebuilt stacks as serverless, only to drown in cold starts and vendor lock-in. Then they migrated everything back to containers, facing scaling headaches and inflated bills. The reality in 2026 is pragmatic: the best systems use both, deliberately.
The hybrid architecture pattern — blending containerized microservices with serverless functions — isn't a compromise. It's an architectural decision that maps each workload to the runtime that serves it best. Let's explore how to design, implement, and operate these systems in production.
Why Hybrid Beats Both Poles
Pure serverless struggles with long-running processes, sustained high throughput, and stateful workloads. Containerized microservices struggle with unpredictable traffic spikes and the overhead of managing scaling infrastructure. The hybrid pattern addresses each weakness with the other's strength.
Consider an e-commerce platform. Product catalog queries hit predictable traffic — perfect for containerized services on Kubernetes. Checkout and payment processing spike during sales events. Those are ideal for serverless functions that scale to zero between requests.
Core Patterns for Hybrid Systems
The Event-Driven Boundary Pattern
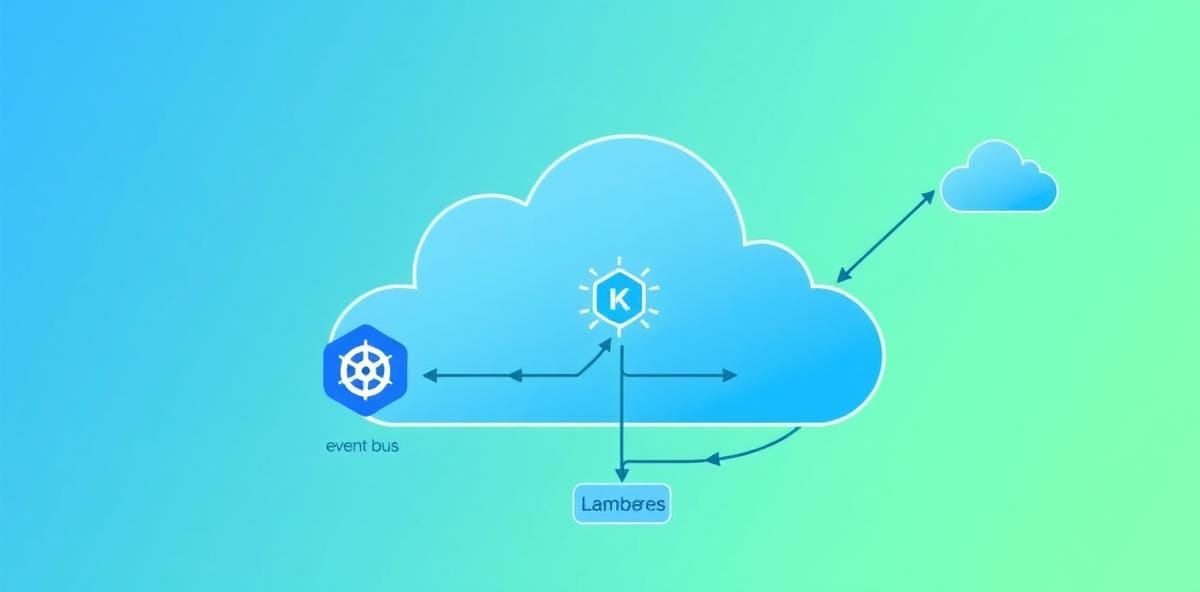
The most common hybrid pattern uses an event bus as the boundary between serverless and microservice tiers. Containerized services own stateful domains — user accounts, inventory, order management — and publish domain events. Serverless functions consume those events to trigger downstream workflows without blocking the source service.
OrderService (Kubernetes)
├── publishes → "order.created" event
├── publishes → "order.paid" event
└── publishes → "order.shipped" event
NotificationFunction (Serverless)
├── subscribes → "order.created" → sends confirmation email
├── subscribes → "order.shipped" → sends tracking update
└── subscribes → "order.delayed" → sends apology + discount
AnalyticsFunction (Serverless)
├── subscribes → "order.created" → updates real-time dashboard
└── subscribes → "order.paid" → aggregates revenue metricsThis pattern gives you the best of both worlds: your core services remain fast and responsive without being bogged down by secondary workloads, while your serverless functions scale independently based on event volume.
The Compute Boundary Pattern
Some workloads benefit from running inside the same service but using different runtimes. A containerized API gateway might route certain endpoints to inline serverless functions. This is particularly effective for request transformation, authentication middleware, and light data enrichment that doesn't warrant a separate service.
Gateway Service (Container, always running)
├── /api/users → routes to User Microservice (container)
├── /api/search → routes to Search Microservice (container)
├── /api/health → handled by inline serverless health check
└── /api/cors-preflight → handled by inline serverless CORS handlerThe compute boundary pattern reduces service count while maintaining clear separation of concerns. The container handles routing and orchestration; serverless handles lightweight, stateless operations.
The Stateful Worker Pattern
For workloads that require both long-running execution and bursty scaling, the stateful worker pattern uses containers for the worker process and serverless for the orchestration layer. Temporal or similar workflow engines manage the state machine, while individual steps execute as either containers or functions depending on their characteristics.
Workflow: Video Processing Pipeline
├── Step 1: "Validate Upload" → Serverless function (fast, stateless)
├── Step 2: "Extract Metadata" → Serverless function (fast, stateless)
├── Step 3: "Transcode Video" → Container worker (long-running, GPU)
├── Step 4: "Generate Thumbnails" → Serverless function (bursty)
└── Step 5: "Update Database" → Container service (stateful)The workflow engine provides durability and retry semantics while each step uses the runtime that fits its execution profile.
Operational Challenges You Will Face
Hybrid architectures solve many problems but introduce their own. Here are the ones that catch teams off guard in production.
Observability fragmentation. Your traces span two completely different telemetry systems — container service mesh for the Kubernetes side, and cloud provider tracing for the serverless side. You need a unified tracing layer that correlates spans across both. OpenTelemetry with a backend like Grafana Tempo or Jaeger solves this, but the configuration requires deliberate effort.
Cold start surprises. Serverless functions that haven't been invoked in hours will cold start. If your event-driven boundary means a user request triggers a serverless function that then calls a container service, that cold start adds latency to the user-facing request. Mitigate with provisioned concurrency for latency-sensitive paths, or restructure to avoid cross-boundary calls in the critical path.
Deployment coordination. Updating a containerized service and its dependent serverless functions requires coordinated deployments. If the serverless function expects an event schema that the container service hasn't shipped yet, you get runtime errors. Use schema registries and versioned event contracts to prevent this.
Cost opacity. Container costs are predictable per-node. Serverless costs are unpredictable per-invocation. A traffic spike that looks like a win for serverless can become an expensive surprise. Implement per-function cost allocation and set budget alerts. Monitor the breakeven point where serverless becomes more expensive than reserved containers.
Building Your Hybrid System
Start by auditing your existing services. Categorize each workload along two axes: traffic predictability (steady vs. spiky) and execution duration (sub-second vs. minutes). Services that are steady and fast belong in containers. Services that are spiky and fast belong in serverless. Services that are spiky and long-running need the stateful worker pattern. Services that are steady and long-running should stay in containers with proper autoscaling.
Implement the event bus first. Whether you choose Kafka, AWS EventBridge, or a managed event streaming service, the event layer is the backbone that makes hybrid architecture work. Define your domain events before writing any code. Establish naming conventions, versioning rules, and schema validation up front.
Then migrate incrementally. Pick one workload — ideally something spiky with clear event boundaries — and move it to serverless. Measure the difference in latency, cost, and operational complexity. Use those measurements to inform the next migration decision. The hybrid architecture is not a big-bang rewrite; it's a series of deliberate, measurable experiments.
The teams that win with hybrid architectures in 2026 aren't the ones who picked the right runtime. They're the ones who picked the right boundary — the line between what runs where, and how those pieces communicate reliably.


Comments