
For years, the centralized data lake was the default architecture pattern for organizations that dealt with serious data workloads. You built one massive warehouse, dumped everything into it, and let data engineers build pipelines from the edges toward the center. It worked fine until it didn't — scaling became a nightmare, teams bottlenecked on shared infrastructure, and the "lake" turned into a swamp faster than anyone anticipated.
In 2026, Data Mesh has moved from academic concept to production reality. It is no longer a theoretical architecture you read about at conferences. It is the dominant pattern for data-intensive systems, and understanding how it works matters for every engineer who designs systems handling serious data workloads.
What Data Mesh Actually Is (Beyond the Buzzwords)
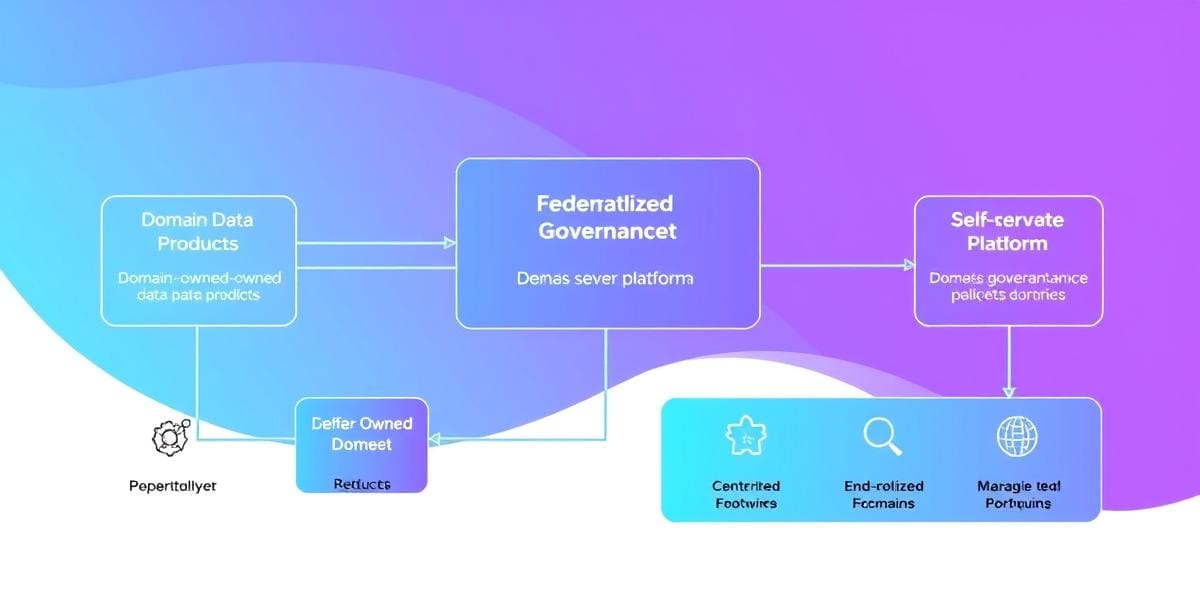
Data Mesh is not a product. It is not a tool you install. It is an organizational and architectural paradigm built on four principles:
- Domain-oriented decentralization: Each business domain owns its data end to end — collection, storage, quality, and access. There is no central data team hoarding pipelines.
- Data as a product: Data outputs are treated like products. They have clear SLAs, documentation, discoverability, and trustworthiness guarantees. You do not ship raw tables into the wild without treating them as deliverables.
- Self-serve data infrastructure: The platform team builds tooling that lets domains publish data without writing custom infrastructure code every time. Think standardized pipelines, automated governance, and one-click deployment.
- Federated computational governance: Global policies (security, compliance, quality standards) are defined centrally but enforced through the same self-serve platform. You get consistency without centralization.
The key insight: Data Mesh solves an organizational scaling problem with architecture. As long as one team manages all data pipelines, growth kills throughput regardless of infrastructure size. Decentralization becomes mandatory beyond a certain team count.
Why 2026 Is the Inflection Point
Data Mesh was popularized in 2020 by Zhamak Dehghani at ThoughtWorks. But theory and production are different stories. Several convergence factors made 2026 a turning point:
- Platform engineering maturity: Internal developer platforms reached the polish needed for self-serve data infrastructure without requiring each domain to hire dedicated platform engineers.
- Cloud-native storage economics: Object storage costs dropped enough that decentralized domain stores are economically viable compared to centralized lakes.
- AI workloads demand fresh data: RAG pipelines, fine-tuning datasets, and real-time feature stores cannot tolerate latency from routing through a central data team.
- Regulatory pressure: Data residency requirements across regions make centralized storage increasingly impractical for global companies.
Production Architecture: How It Actually Looks
A production Data Mesh coexists with your existing warehouse. Here is the typical stack:
| Layer | Technology Examples (2026) | Purpose |
|---|---|---|
| Data Storage | Snowflake, BigQuery, Delta Lake on S3 | Domain-owned stores per product |
| Ingestion | Flyte, Dagster, Airflow with domain configs | Automated pipeline deployment per domain |
| Discovery | DataHub, OpenMetadata, Amundsen | Catalog and search across products |
| Governance | Apache Ranger, Immuta, custom policy engines | Federated access control and auditing |
| Serving | REST APIs, GraphQL, materialized views, feature stores | Consumption for downstream consumers |
The platform team maintains the ingestion framework, catalog service, and governance layer. Each domain deploys its own data product using that infrastructure. A team owning user analytics can publish their events pipeline in hours instead of weeks.
Common Pitfalls and How to Avoid Them
The literature talks about Data Mesh like it is straightforward. In practice, organizations stumble on several specific issues:
Pitfall 1: Treating it as technical migration instead of organizational change.
Data Mesh fails when leadership expects engineers to simply "move data to domains" without restructuring accountability. Domain teams must own data quality, not just pipeline code. If you cannot assign a product owner to each data product, start elsewhere first.
Pitfall 2: Building a platform nobody uses.
The self-serve infrastructure is the linchpin. If it is harder to publish a well-governed data product through the platform than to hack together a raw table dump, your Data Mesh collapses back into chaos. Invest heavily in the platform team and measure adoption metrics religiously.
Pitfall 3: Ignoring cross-domain dependencies from day one.
Domain A's data product inevitably needs data from Domain B. Without federated governance, this creates either informal dependency chains or re-centralization pressure that defeats the purpose. Establish contract-driven interfaces between domains early — define schemas, versioning, and SLA expectations before teams start consuming outputs.
Pitfall 4: Trying to do it all at once.
Successful implementations started with two or three willing domains as pilots. They proved the platform worked, demonstrated quality improvements, then expanded. Pick domains where data ownership is already clear and teams are motivated.
When Not to Use Data Mesh
Data Mesh is powerful but not universal. Skip it if:
- Fewer than 15 people touching data infrastructure. The coordination overhead outweighs benefits at this scale.
- A single analytical workload (e.g., one BI dashboard). A traditional warehouse is simpler and cheaper.
- Teams lack the maturity to treat data as a product — unable to commit to SLAs, documentation standards, or backward-compatible changes.
In these cases, a well-run centralized model with clear internal SLAs serves you better. Data Mesh is a scaling solution, not a silver bullet for poor data practices.
The Bottom Line
Data Mesh represents the recognition that data architecture cannot scale independently of organizational structure. As your company grows, the bottleneck shifts from technology to coordination — and no amount of automation fixes an org chart problem.
In 2026, the tools caught up with the theory. Platform engineering gave us the self-serve infrastructure Data Mesh requires. AI workloads created urgency that centralized pipelines cannot meet. Regulatory complexity made distributed ownership a business necessity.
If your organization faces data scaling challenges, start small, invest in the platform, and remember: the hardest part is never technical. It is always getting people to agree on who owns what.

Comments